What the heck is Hext?
Hext Reference
Starting with an Example
# Extract links and their text
<a href:link @text:title />
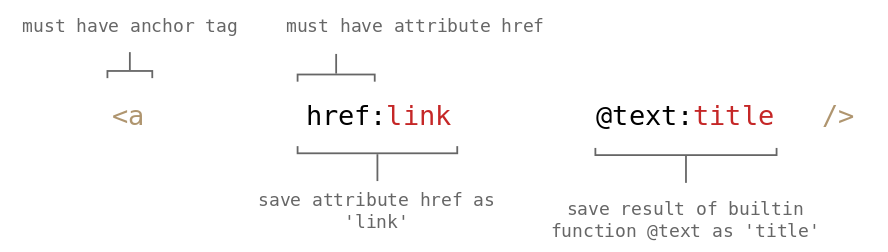
<!-- Html input: -->
href="one.html" Page 1
href="two.html" Page 2
href="three.html"Page 3
Hext's output:
{"link": "one.html", "title": "Page 1"}
{"link": "two.html", "title": "Page 2"}
{"link": "three.html", "title": "Page 3"}The Big Picture
Hext's strength is that you can put together something that looks like the HTML you want to extract data from. Hext templates can be thought of as a counterpart to web templates. Web developers typically use templates to embed data in HTML and that's why most content on the web does have some sort of structure which is to Hext's advantage.
The template on the right
below collects all submissions
from a Hackernews listing. For example, if applied to
news.ycombinator.com/newest
you'll get a list of the most recent submissions with each item
containing the rank,
title, href, score, user and comment_count.
There are multiple ways to use Hext:
- The htmlext command line utility applies Hext to HTML documents and returns JSON containing the captured data.
- The libhext library contains a Hext parser but also lets you build a Hext rule tree manually.
- The Hext language bindings: Python, Node, JavaScript, Ruby, PHP
<tr class="athing">
{ <span class="rank" @text:rank /> }
{ <span class="titleline">
<a href:href @text:title />
</span> }
</tr>
<?tr> {
<span class="subline">
<span class="score" @text:score />
<a @text:user />
<a:last-child @text:filter(/\d+/):comment_count />
</span>
} </tr>
Also, you can test Hext in the "Try Hext in your Browser" section: Just paste any HTML from the web into the editor and have a go!
Another Example
Notice how only the first span is matched for id in the example below. This is because rules take turns to match elements. The second <span> gets tested by the rule for image, which doesn't match and the element gets skipped. The rule then continues with <img>, which matches. Then, the first rule (id) takes over again. And indeed it matches the third <span>, but the result is discarded because the second rule (image) doesn't match: there are no more elements left.
<a href:link>
<span @text:id />
<img src:image />
</a>
<!-- Html input: -->
href="/coffee"
#1
Coffee
src="coffee.jpg"
turns nights into code
href="/beer"
#2
Beer
src="beer.jpg"
improves dance skill by 70%
Hext's output:
{
"id": "#1",
"image": "coffee.jpg",
"link": "/coffee"
}
{
"id": "#2",
"image": "beer.jpg",
"link": "/beer"
}How Hext Matches Elements
A Hext template is a set of rules that is matched against an HTML document. Each HTML element is tested by the first rule of a Hext template. A rule begins with either an HTML tag or an asterisk which matches every HTML element.
# match every element with any tag
<* />
# match every <div> element
<div />
Rules may have children. If a rule matches an HTML element, the rule's children are matched against the element's children, and must each produce at least one match.
# match <a> elements that have at
# least one child element <img>
<a><img /></a>
Rules may have siblings. If a rule matches an HTML element, all the rule's siblings are matched against the element's siblings. While adjacency is not required, matching elements must still appear in the same order as their rule counterparts.
# match <h1> elements that are followed
# by a <p> element
<h1/><p/>
Rules may have nested rules. If a rule matches an HTML element, all the rule's nested rules are matched against the element's inner HTML. A nested rule can find a match at any depth.
# match <div> elements that have a
# descendant <a> at any depth
<div> { <a/> } </div>
Rules may be optional. A Hext template only matches if each rule finds its match, unless it is marked optional with a question mark. These rules are simply skipped if no match is found. Mandatory rules always take precedence over optional rules.
# match <h1>, optionally followed by <time>,
# followed by a paragraph
<h1/><?time/><p/>
Rules may be greedy. A rule marked with a plus sign does not stop at
the first match, instead it continually searches for a match until a mandatory
rule takes precedence or until there are no more elements left.
A greedy rule can also be made optional, that is, it may match none or many.
# match <h1>, followed by at least one <p>
<h1/><+p /># match <h1>, followed by zero or more <p>
<h1/><?+p />
Rules may contain match patterns. Match patterns
further refine which HTML elements to match. There are three kinds
of match patterns: Attribute matches,
Built-in Function matches and
Element Traits.
Attributes may be compared against a string or a regular expression.
There are six match operators that
determine the type of comparison:
= contains word, *= contains,
^= begins with, $= ends with,
== identical and =~/regex/. Regular
expressions may also be embedded in quotes, e.g. =~"\d+",
which is particularly useful when matching URLs.
Match patterns may be negated by an exclamation mark.
# match <a> having attribute "name"
<a name />
# match <a> having attribute "href"
# beginning with "https:"
<a href^="https:" />
# match <a> having attribute href containing
# the string "post-" followed by a number
<a href=~/post-\d+/ />
# match <a> not having attribute "href" beginning
# with "https:"
<a href^="https:"! />
Built-in functions turn an HTML element
into a string. As with attributes,
match operators may be used to
test for specific contents. There are three built-in functions:
@text, @inner-html and
@strip-tags.
@text is the most powerful, as it turns an HTML element into
clean and readable text.
# match <h1> whose content starts with "News: "
<h1 @text^="News: " />
# match <h1> whose content matches a case
# insensitive regex
<h1 @text=~/section \d+.\d+/i />
Element traits describe the position of an
HTML element relative to its parent or general properties,
for example its amount of children or attributes. The intent is to
replicate CSS pseudo-classes.
Chained traits require elements to match each trait.
:not(traits) negates element traits.
# match <li> who are the first child of their parent
<li:first-child />
# match <li> who are the first and the last child of
# their parent (i.e. the only child)
<li:first-child:last-child />
# match every third <li>
<li:nth-child(3n) />
# match <li> that are not the first child
<li:not(:first-child) />
How Hext Captures Data
Rules may contain captures. After a successful and complete match of a Hext template the data is extracted. There are two possible sources for data: HTML attributes and the result of built-in functions. Each capture must be named.
# match <a> having attribute "href" and store
# the attribute's value as "link"
<a href:link />
# match <article> and store its content as "content"
<article @text:content />
Attribute captures may be suffixed by a question mark, indicating that the attribute is optional, i.e. a matching element may have this attribute, but doesn't need to.
# match <a> having attribute "href" and optionally
# having attribute "name", store their values in
# "link" and "anchor"
<a href:link name:anchor? />
Captures may contain string pipes.
String pipes transform the content of an HTML attribute or the result of a
built-in function.
String pipes may be chained.
# match <a> having attribute "href", prepend
# "https://example.com/" to its value and store
# it as "url"
<a href:prepend("https://example.com/"):url />
A particularly useful string pipe is :filter. It transforms a string according to a regular expression. This regular expression may contain a capture group which isolates a result from the rest of the match.
# extract the first number, store as first_num
<h1 @text:filter(/[0-9]+/):first_num />
# extract digits only, store as phone_nr
<div @text:filter(/Phone: ([0-9]+)/):phone_nr />
Limitations
- Hext operates on a bare bones HTML parse tree. It has no knowledge of Javascript or CSS.
- All input is stubbornly treated as UTF-8.
- Hext only extracts strings and provides little means to modify the data.
- There's HTML out there that won't work well with Hext. But such is life.
Hext aims to make simple extractions easy; if you have bigger problems you probably need bigger tools ¯\_(ツ)_/¯
See also:
- Xidel: Xidel is a command line tool to download and extract data from HTML/XML pages as well as JSON APIs. Handles multiple extraction methods, including XPath/XQuery, CSS3 selectors and "Templates" which are similar to Hext. If htmlext doesn't cut it for you, this marvelous tool has it all.
- QtWebKit: A full-blown browser that allows access to its internals and can therefore be (ab-)used to extract content.
- Python's BeautifulSoup, Ruby's Nokogiri and Node's cheerio.
Element Traits
Element traits describe the position of an HTML element relative to its parent
or general properties, for example its amount of children or attributes.
The intent is to replicate CSS pseudo-classes.
Chained traits require elements to match each trait.
:empty
:child-count(<amount>)
Select elements that have a certain amount of children.
Text nodes are not considered to be children, i.e. an element that
only contains text is considered to be empty.
# match: <div></div>, <div>text</div>, ..
<div:empty />
# match: <div><a></a><b></b></div>,
# <div>Children: <a></a><b></b></div>, ..
<div:child-count(2) />
:attribute-count(<amount>)
Select elements that have a certain amount of attributes.
# match: <div></div>, <div><a></a></div>
<div:attribute-count(0) />
# match: <div class="" style="" ></div>
# <b data-a="" data-b=""></b>
<*:attribute-count(2) />
:not(<:trait>)
Select elements that don't match certain traits.
# match all elements that are not empty
<*:not(:empty) />
# match all elements that are not empty and
# do not have an attribute count of two
<*:not(:empty:attribute-count(2)) />
:type-matches(<regex>)
Select elements with tag names that match the given regex.
# match paragraphs or headings
<*:type-matches(/^(p)$|^(h[1-6])$/) />
# match <CustomTag> or <custom-tag>
<*:type-matches(/^custom[-]?tag$/i) />
:first-child
:first-of-type
:last-child
:last-of-type
:only-child
:nth-child(<nth-pattern>)
:nth-of-type(<nth-pattern>)
:nth-last-child(<nth-pattern>)
:nth-last-of-type(<nth-pattern>)
:only-of-type
Select elements by position within their parent.
<nth-pattern> may be given in the form of an+b or as
the shorthands even and odd.
See
MDN for a detailed description.
# <ul>
# <li>These pseudo</li> <!-- match -->
# <li>classes </li>
# <li>work just </li> <!-- match -->
# <li>like they </li>
# <li>do in CSS </li> <!-- match -->
# </ul>
<li:nth-child(2n+1) />
Match Operators
Match operators compare an attribute's value or the output of a built-in function against a string or a regular expression.
="<string>"
Matches subjects that contain all of the given words in any order. Word boundaries are the beginning and end of the subject or spaces.
# match: class="item",
# class="item menu", ..
# does not match: class="first-item",
# class="menuitem", ..
<* class="item" />
# match: class="article sub head",
# class="head article", ..
# does not match: class="particle head",
# class="article-head", ..
<* class="article head" />
*="<string>"
Matches subjects that contain the given string.
# match: href="http://youtube.com/",
# href="youtube", ..
<* href*="youtube" />
^="<string>"
Matches subjects that begin with the given string.
# match: <p>Hello, this is HAL</p>,
# <p>Hello</p>, ..
# does not match: <p>hello</p>,
# <p>Oh, Hello</p>, ..
<* @text^="Hello" />
$="<string>"
Matches subjects that end with the given string.
# match: href="igel.jpg", href="franz.jpg", ..
<* href$=".jpg" />
=="<string>"
Matches subjects that are equal to the given string.
# match: class="left aligned list"
# does not match anything else
<* class=="left aligned list" />
=~/<regex>/[opt]
=~"<regex>"[opt]
Matches subjects that match the given regular expression.
There are two options for regular expressions:
i: case insensitive
and c: collate (locale aware character groups)
# match: class="menuItem-23",
# class="menuItem-42-23", ..
<* class=~/item-\d+/i />
String Pipes
String pipes transform strings before they are captured. String pipes can be chained.
:trim
:trim("<characters>")
Trims characters from the beginning and the end of a string. Trims spaces by default. If given an argument, trims all given characters. Does not handle unicode.
# trim all left and right spaces
<* title:trim:name />
# trim all left and right spaces and dashes
<* title:trim(" -"):name />
:collapsews
Trims whitespace from beginning and end and collapses multiple whitespace to a single space.
# Turns this:
# <a title=" Lots of spaces in this title">
# Into this:
# "Lots of spaces in this title"
<* title:collapsews:name />
:tolower
:toupper
Changes all characters to lower or upper case. Does not handle unicode.
<a title:toupper:link_title />
<a title:tolower:link_title />
:prepend("<string>")
:append("<string>")
Prepends or appends a given string.
# turn relative URLs into absolute URLs
<a href:prepend("https://example.com/"):url />
# append foo
<a title:append(" ..and foo!"):title />
:filter(/<regex>/[opt])
Filters a string according to a given regex.
A regex containing a capture group will produce only the
matched content of that capture group, otherwise the whole
regex match is returned. All capture groups after the first
one will be ignored.
There are two options for regular expressions:
i: case insensitive
and c: collate (locale aware character groups)
# save the trailing number contained in attr. href
<a href:filter(/\d+$/):user_id />
# save the number after "post-"
<a href:filter(/post-(\d+)/):post_id />
:replace(/<regex>/[opt], "<string>")
Replaces a portion matched by the given regex with a string.
Backreferences can be used to address capture groups
(detailed description).
There are two options for regular expressions:
i: case insensitive
and c: collate (locale aware character groups)
# replace all instances of foo with bar
<p @text:replace(/foo/, "bar"):bar_text />
# remove all numbers
<p @text:replace(/\d+/, ""):nonum />
# use capture groups and backreferences
<h1 @text:replace(/(\d+): (.*)/, "$2 ($1)"):head />
Built-in Functions
Built-in functions transform an element into a string.
@text
Returns the inner text. Trims left and right whitespace and collapses
multiple whitespace to a single space.
The content of some elements will be embedded in spaces
(basically all non-inline elements, like <div> or <h1>).
The intent is to mimic functions like jQuery's text(), IE's
innerText() or textContent().
Does not strip
metadata content.
# Turns this:
# <article>
# <h1> Which Highway?</h1>Highway 61!
# </article>
# Into this:
# "Which Highway? Highway 61!"
<article @text:content />
@inner-html
Serializes the inner HTML to a string.
# Turns this:
# <div><h1>Which Highway?</h1> Highway 61! </div>
# Into this:
# "<h1>Which Highway?</h1> Highway 61! "
# And the filter turns it into this:
# "Highway 61"
<div @inner-html:filter(/Highway \d+/):number />
@strip-tags
Returns the inner HTML with all tags removed.
# Turns this:
# <div><h1>Which Highway?</h1> Highway 61!</div>
# Into this:
# "Which Highway? Highway 61! "
<div @strip-tags:content />